



Python 基础到高级
基础教程
推荐 1:Python 官网
推荐 2:极客教程
推荐 3:清华源镜像站
国内下载镜像:
- 清华:https://pypi.tuna.tsinghua.edu.cn/simple
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 豆瓣:https://pypi.douban.com/simple/
- 中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
- 华中理工大学:http://pypi.hustunique.com/
- 山东理工大学:http://pypi.sdutLinux.org/
设置镜像源的命令:
python# (1)临时使用 $ pip install -i https://pypi.douban.com/simple/ packagename # 检查是否配置完成 $ pip config listpython# (2)设置为永久 # window设置镜像源 $ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/ # Linux设置镜像源 $ echo "[global]" >> ~/.pip/pip.conf $ echo "index-url=https://pypi.tuna.tsinghua.edu.cn/simple" >> ~/.pip/pip.conf # 检查是否配置完成 $ pip config list
速查表
注意:
要是感觉看不清楚,
PC端可以按Ctrl + 鼠标滚轮前滚/后滚来缩放网页大小.
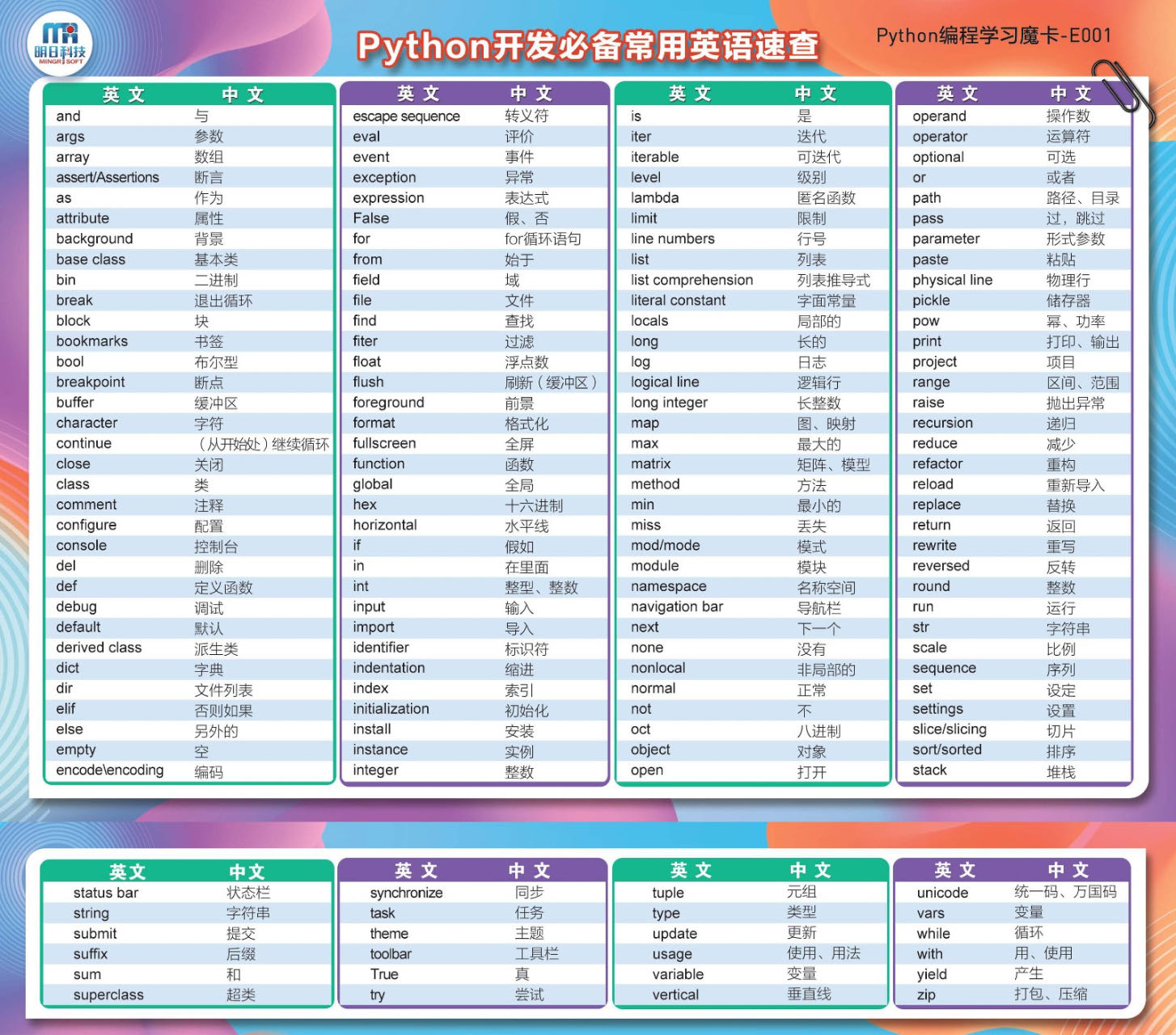
开发必备常用英语速查
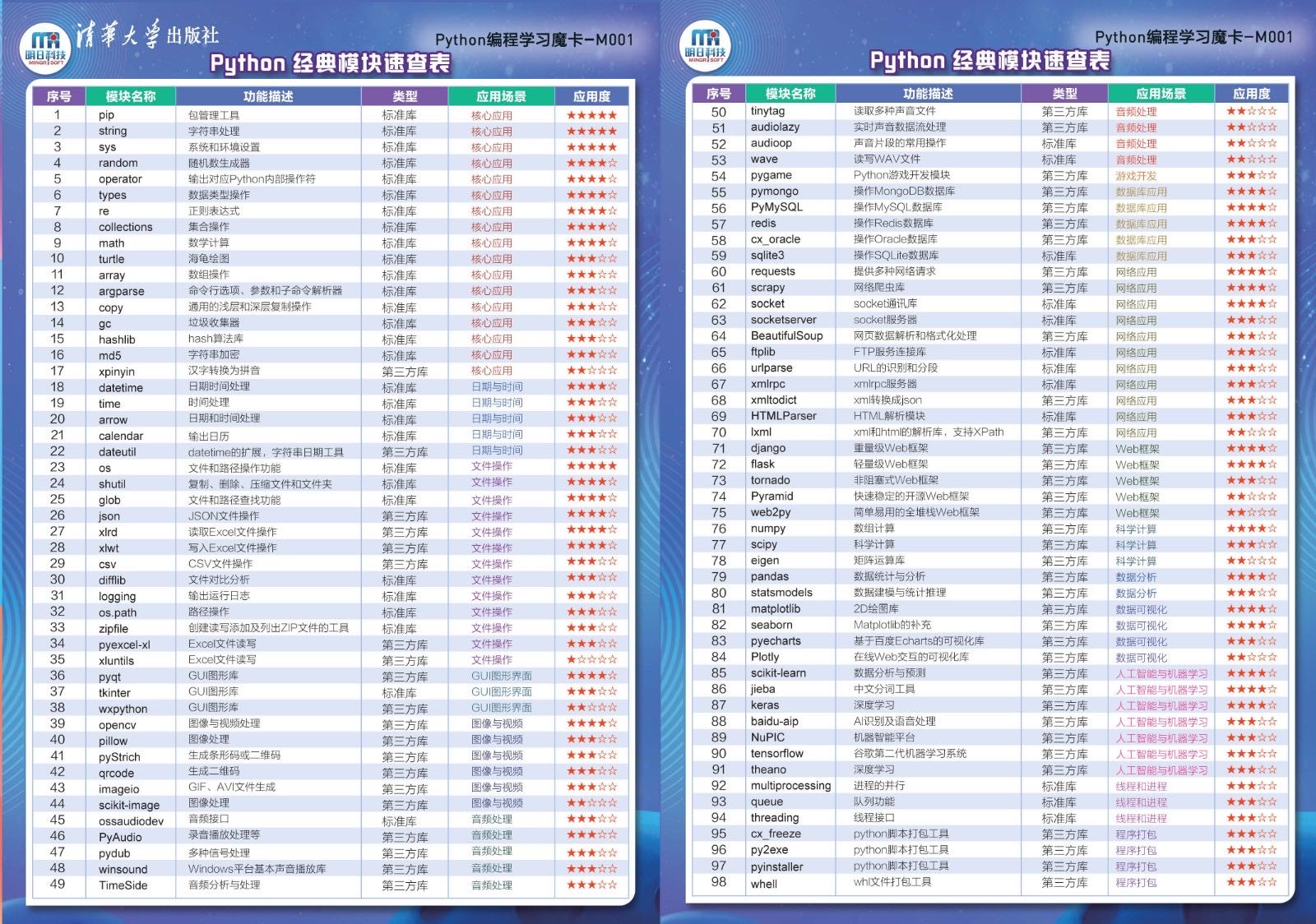
经典模块速查表
内置函数速查表

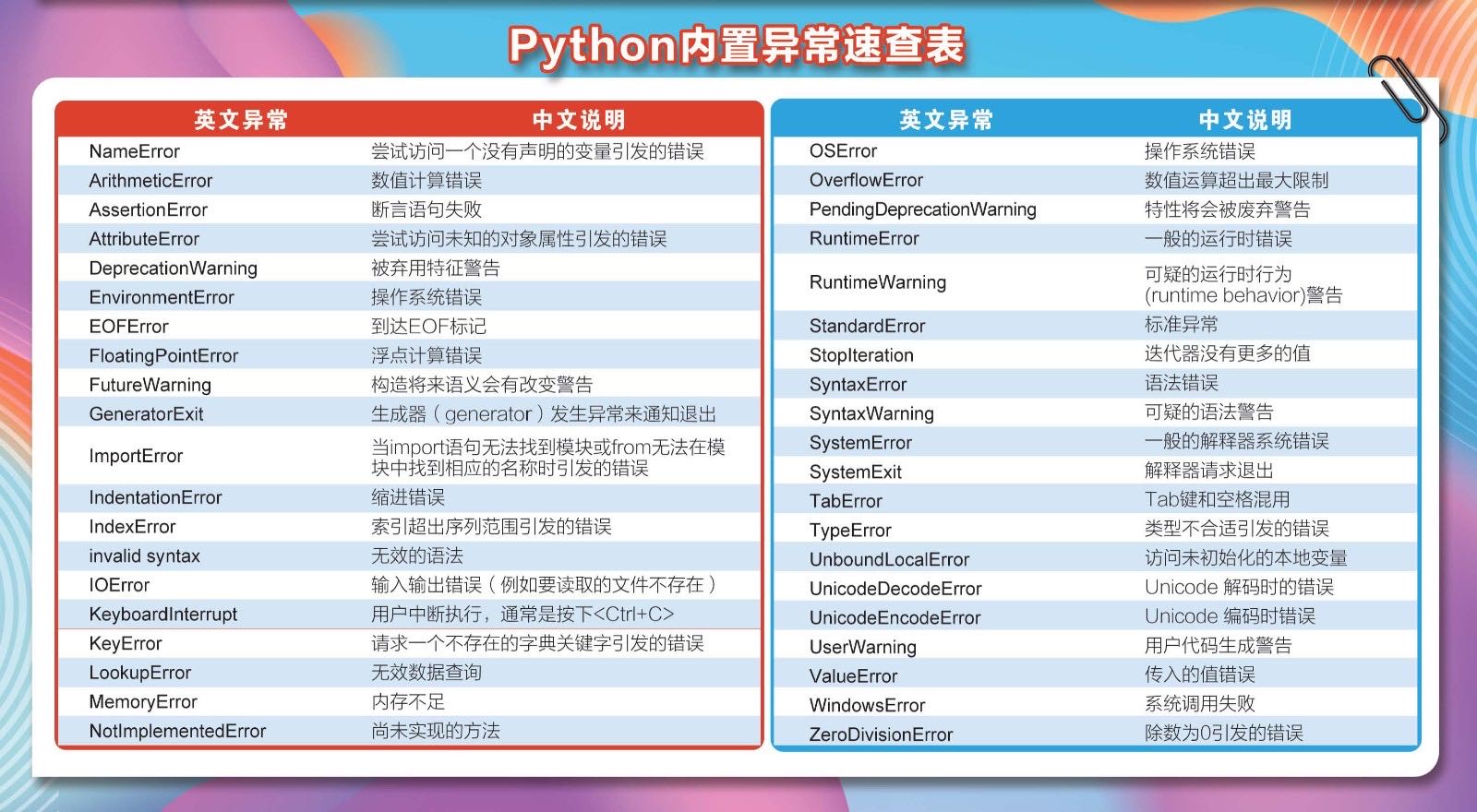
内置异常速查表
爬虫
1. 数据解析
2. Selenium
初步尝试
python
import time
# 导入selenium
from selenium import webdriver
# 创建驱动对象
driver = webdriver.Chrome() # 创建驱动对象
url = 'https://www.baidu.com/'
driver.get(url) # 打开浏览器
content = driver.page_source # 获取网页源码
print(content) # 打印内容
time.sleep(5) # 睡眠 5 秒钟
driver.close() # 关闭浏览器寻找元素的方法
- 新版
selenium寻找元素的API方法如下:
python
class By:
"""Set of supported locator strategies."""
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"- 定位元素示例
python
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() # 创建驱动对象
url = 'https://www.baidu.com/'
driver.get(url) # 打开浏览器
# 通过 ID 选择器寻找元素
button1 = driver.find_element(by=By.ID, value='su')
# 通过Xpath语法寻找元素
button2 = driver.find_element(by=By.XPATH, value='//input[@id="su"]')
# 通过css选择器寻找元素
button3 = driver.find_element(by=By.CSS_SELECTOR, value='#su')- 获取属性
python
btn_value = button.get_attribute('value') # 写入对应的属性名,即可获得属性值
print(value)- 获取标签文本
python
# 获取标签的文本内容
print(button.text)- 获取标签名
python
# 获取标签名
print(button.tag_name)驱动交互行为
- 输入文本
python
custom_value = input("请输入内容: ")
inputElement.send_keys(custom_value)- 点击
python
button.click()- 执行
js脚本
python
js_bottom = 'document.documentElement.scrollTop=10000' # 划到底部
driver.execute_script(js_bottom)3. requests
安装
python
$ pip install requests一个类型六个属性
response 的属性以及类型,以下简写为 r
python
r :models.Response
r.text :获取网站源码
r.encoding :访问或设置编码方式
r.url :获取请求的url
r.content :响应的字节类型(返回二进制数据,一般用于获取媒体的数据)
r.status_code :响应的状态码
r.headers :响应的头信息返回对象类型: Response
py
import requests
url = 'https://www.baidu.com/'
response = requests.get(url)
print(type(response)) # Response 类型编码: 默认 None
py
import requests
url = 'https://www.baidu.com/'
response = requests.get(url)
response.encoding = 'utf-8' # 默认是 None
print(response.text)Flask 框架
正在开发中...
Django 框架
官网
推荐:前往官网
下载包
python
$ pip install django创建工程
python
$ django-admin startproject myapp新增应用
python
$ python manage.py startapp newapp创建超级管理员
python
$ python manage.py migrate # 执行一次django内部数据库初始化迁移操作
$ python manage.py createsuperuser # 创建超级管理员用户
$ # Todo...启动项目
python
$ python manage.py runserver 80python
$ python manage.py runserver 0.0.0.0:8080正在开发中...
常用业务功能
QQ 邮箱验证码
后端代码
推荐
参考:解决跨域请求的博客
python
# 后端服务器
EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'
EMAIL_HOST = 'smtp.qq.com' # SMTP地址 例如: smtp.163.com
EMAIL_PORT = 25 # SMTP端口 例如: 25
EMAIL_HOST_USER = '1043744584@qq.com' # qq的邮箱 例如: xxxxxx@163.com
DEFAULT_FROM_EMAIL = "1043744584@qq.com" # 短信来信人
EMAIL_HOST_PASSWORD = 'dpssxjabyofebcef' # 邮箱授权码(需要在QQ邮箱中开启)
EMAIL_SUBJECT_PREFIX = u'django' # 为邮件Subject-line前缀,默认是'[django]'
EMAIL_USE_TLS = True # 与SMTP服务器通信时,是否启动TLS链接(安全链接)。默认是false
EMAIL_FROM = '1043744584@qq.com' # 显示邮箱发送人的昵称python
# 需要下载第三方解决跨域请求的包
# pip install django-cors-headers
ALLOWED_HOSTS = ['*']
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'corsheaders', # 注册跨域请求的应用
'django.contrib.messages',
'django.contrib.staticfiles',
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'corsheaders.middleware.CorsMiddleware', # 添加中间件
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware', 需要注释掉 CSRF
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
CORS_ALLOW_CREDENTIALS = True
CORS_ORIGIN_ALLOW_ALL = True
CORS_ORIGIN_WHITELIST = ()
CORS_ALLOW_METHODS = (
'DELETE',
'GET',
'OPTIONS',
'PATCH',
'POST',
'PUT',
'VIEW',
)
CORS_ALLOW_HEADERS = (
'authorization',
'content-type',
# 常用就上面两个
'XMLHttpRequest',
'X_FILENAME',
'accept-encoding',
'dnt',
'origin',
'user-agent',
'x-csrftoken',
'x-requested-with',
'Pragma',
)python
from django.core.mail import send_mail
from django.http import HttpResponse
from .settings import EMAIL_FROM
import random
import json
# 发送邮箱验证码
def send_verify_code(request):
# (1) application/json
# email = json.loads(request.body).get('email')
# (2) x-www-form-urlencoded
# email = request.POST['email']
if request.method == 'POST':
# 获取用户邮箱
whose_email = json.loads(request.body).get('email')
string = 'abcdefghijklmnopqrstuvwxyz1234567890'
# 生成 4 随机验证码
verify_code = ''
print(verify_code)
for i in range(4):
char = string[random.randint(0, 35)]
verify_code += char
# 发送邮件
subject = '极客兔验证码' # 邮件标题
message = f'Your verification Code is: {verify_code}' # 邮件内容
email_from = EMAIL_FROM # 来信人
email_to = whose_email # 收件人
send_status = send_mail(
subject=subject,
message=message,
from_email=email_from,
recipient_list=[email_to]
)
print("发送状态: ", send_status) # 发送成功为1
if send_status:
return HttpResponse(json.dumps({
'status': 200,
'msg': '邮件发送成功, 请查收!',
'verify_code': verify_code
}, ensure_ascii=False))
else:
return HttpResponse(json.dumps({
'status': 400,
'msg': '邮件发送失败,请检查邮箱是否正确!'
}, ensure_ascii=False))
else:
return HttpResponse(json.dumps({
'status': 400,
'msg': '请求方式错误!'
}, ensure_ascii=False))前端代码
bash
$ npm i axios bootstrap@5.3.3ts
import axios from 'axios'
export default axios.create({
baseURL: 'http://127.0.0.1:8080',
timeout: 15000
})vue
<script setup lang="ts">
import { ref } from 'vue'
import request from './utils'
/**
* 倒计时变量
*/
const count = ref(60)
const SendVerifyCode = async () => {
/**
* 发送验证码、控制倒计时变化
*/
let timer = setInterval(() => {
count.value--
if (count.value <= 0) {
clearInterval(timer)
count.value = 60
return
}
}, 1000)
const email = '361024912@qq.com' // 替换成用户自己的邮箱
const code = await request.post('/get-code/', { email })
console.log(code)
}
</script>
<template>
<div class="input-group my-3 px-3">
<input type="text" class="form-control" placeholder="输入验证码" />
<button
class="btn btn-outline-primary input-group-text"
@click="SendVerifyCode"
>
{{ count !== 60 ? `等待 ${count} 秒, 重新发送` : '发送验证码' }}
</button>
</div>
</template>
<style scoped lang="scss"></style>支付宝沙箱支付
推荐
参考:博客教程
1、下载 SDK
bash
$ pip3 install python-alipay-sdk --upgrade -i https://pypi.douban.com/simple/2、配置公钥和私钥
① 支付宝扫码登录: 支付宝开放平台
3、配置
python
import os
# 支付宝支付相关配置
ALIPAY_SETTING = {
'ALIPAY_APP_ID': "9021000133647342", # 应用ID(上线之后需要改成,真实应用的appid)
'APLIPAY_APP_NOTIFY_URL': None, # 应用回调地址[支付成功以后,支付宝返回结果到哪一个地址下面] 一般这里不写,用下面的回调网址即可
'ALIPAY_DEBUG': False,
# APIPAY_GATEWAY="https://openapi.alipay.com/gateway.do" # 真实网关
'APIPAY_GATEWAY': "https://openapi.alipaydev.com/gateway.do", # 沙盒环境的网关(上线需要进行修改)
'ALIPAY_RETURN_URL': "http://127.0.0.1:8000/alipay/result/", # 同步回调网址--用于前端,支付成功之后回调
'ALIPAY_NOTIFY_URL': "http://127.0.0.1:8000/alipay/result/", # 异步回调网址---后端使用,post请求,网站未上线,post无法接收到响应内容,付成功之后回调
'APP_PRIVATE_KEY_STRING': os.path.join(BASE_DIR, 'keys/app_private_2048.txt'), # 自己生成的私钥,这个就是路径拼接,配置好了,试试能不能点进去
# 支付宝的公钥,验证支付宝回传消息使用,不是你自己的公钥,********
'ALIPAY_PUBLIC_KEY_STRING': os.path.join(BASE_DIR, 'keys/app_public_2048.txt'), # 一定要注意,是支付宝给你的公钥,不是你自己生成的那个
'SIGN_TYPE': "RSA2", # RSA 或者 RSA2 现在基本上都是用RSA2
}python
# 支付宝支付相关配置
from django.conf import settings
from alipay import AliPay, DCAliPay, ISVAliPay
from alipay.utils import AliPayConfig
# 生成支付alipay对象,以供调用
def alipay_object():
alipay = AliPay(
appid=settings.ALIPAY_SETTING.get('ALIPAY_APP_ID'),
app_notify_url=None, # 默认回调 url
app_private_key_string=open(settings.ALIPAY_SETTING.get('APP_PRIVATE_KEY_STRING')).read(),
# 支付宝的公钥,验证支付宝回传消息使用,不是你自己的公钥,
alipay_public_key_string=open(settings.ALIPAY_SETTING.get('ALIPAY_PUBLIC_KEY_STRING')).read(),
sign_type=settings.ALIPAY_SETTING.get('SIGN_TYPE'), # RSA 或者 RSA2
debug=settings.ALIPAY_SETTING.get('ALIPAY_DEBUG'), # 默认 False
verbose=False, # 输出调试数据
# config=AliPayConfig(timeout=50) # 可选,请求超时时间
)
return alipaypython
from django.shortcuts import render
from app03.utils import alipay_obj
from django.conf import settings
from django.http import JsonResponse
# Create your views here.
def wait_pay(request, goods_id, goods_price, goods_title):
""":return 返回付款链接 - 等待支付"""
alipay = alipay_object()
# 生成支付路由: 拼接url --> 返回url
# 电脑网站支付,需要跳转到:https://openapi.alipay.com/gateway.do? + order_string
order_string = alipay.api_alipay_trade_page_pay(
# 这下面的数据,都应该是你数据库的数据,但是我这里做测试,直接写死了
out_trade_no=goods_id, # 商品订单号 唯一的
total_amount=goods_price, # 商品价格
subject='购买' + goods_title + '待付款', # 商品的名称
# 同步回调网址--用于前端,付成功之后回调
return_url=settings.ALIPAY_SETTING.get('ALIPAY_RETURN_URL'),
# 异步回调网址---后端使用,post请求,网站未上线,post无法接收到响应内容,这里需要公网IP,本地测试无法调用使用该方式
notify_url=settings.ALIPAY_SETTING.get('ALIPAY_NOTIFY_URL')
)
# 我这里大概讲一下为什么要有同步/异步,因为同步是前端的,
# 如果前端出现页面崩了,那么校验由后端完成,
# 而且在实际开发中,后端一定要校验,因为前端的校验,可被篡改
url = 'https://openapi-sandbox.dl.alipaydev.com/gateway.do' + '?' + order_string
return JsonResponse({'url': url, 'status': 200})4、向后端获取付款链接
5、成功后的回调处理
安装 Anaconda
推荐:
下载:去官网
注意:
将
anaconda安装的根目录、Scripts、Library/bin等路径添加到系统环境变量 Path中.
bash
$ conda --versionbash
$ conda infobash
$ activate
$ python # 之后再输入 python 即可看到 anaconda 提示的 python解释器科普小知识
编码方式
常见编码方式
ASCII 编码:- ASCII(American Standard Code for Information Interchange)是一种基于拉丁字母的字符编码标准,用于文本通信和数据传输。
- ASCII 编码使用 7 位二进制数来表示每个字符,因此可以表示 128 个字符,包括英文字母、数字和一些符号。
- ASCII 编码不支持非拉丁字母字符,如中文、日文、韩文等。
UTF-8 编码:- UTF-8(Unicode Transformation Format-8)是一种 Unicode 字符编码方式,可表示世界上几乎所有的字符。
- UTF-8 使用不定长的字节序列来表示字符,通常使用 1 到 4 个字节来表示一个字符,因此支持范围广泛的字符集。
- UTF-8 是一种可变长度编码,与 ASCII 兼容,因此在处理英文文本时具有较小的存储开销。
UTF-16 编码:- UTF-16(Unicode Transformation Format-16)是一种 Unicode 字符编码方式,用于表示 Unicode 字符集中的字符。
- UTF-16 使用 16 位编码单元(即两个字节)来表示大部分常见的字符,但对于一些罕见字符,可能需要使用 4 个字节来表示。
- UTF-16 编码在处理较少常用字符时可能会产生较多的存储开销,但在处理常见字符时相对节省空间。
UTF-32 编码:- UTF-32(Unicode Transformation Format-32)是一种固定长度的 Unicode 字符编码方式,每个字符都使用 32 位编码单元表示。
- UTF-32 对于每个字符都使用相同长度的编码单元,因此不会产生变长编码的开销。
- UTF-32 编码在存储上通常会消耗更多的空间,但在处理时更加简单和高效。
ISO-8859 编码:- ISO-8859(International Organization for Standardization 8859)是一系列字符编码标准,用于表示拉丁字母字符集的不同子集。
- ISO-8859 编码是单字节编码,每个字符使用 8 位(即一个字节)表示,因此每种 ISO-8859 编码最多只能表示 256 个字符。
- ISO-8859 编码用于处理特定语言或地区的字符集,如 ISO-8859-1 用于西欧语言,ISO-8859-5 用于西里尔字母等。
GBK 编码:- GBK(Guo Biao Ku, 国标码)是中国国家标准 GB 2312-1980 的扩展,支持包括繁体字在内的更多字符。
- GBK 编码使用双字节编码,每个字符使用 16 位表示,可以表示 21,843 个汉字和符号,覆盖了中文、日文、韩文等语言的常用字符。
- GBK 编码是中文操作系统和应用程序的常用字符编码方式。
GB2312 编码:- GB2312 是中国国家标准,于 1981 年发布,是 GBK 编码的前身。
- GB2312 编码同样使用双字节编码,每个字符使用 16 位表示,覆盖了简体中文的基本字符集。
- GB2312 编码是中文操作系统和应用程序的历史性字符编码方式。
Big5 编码:- Big5 是一种用于繁体中文的字符编码方式,广泛用于台湾、香港等地区。
- Big5 编码同样使用双字节编码,每个字符使用 16 位表示,可以表示繁体中文字符集。
GB18030 编码- GB18030 是中国国家标准,于 2000 年发布,是 GB2312 和 GBK 的扩展,支持更广泛的字符集,包括 Unicode 3.0 中的所有字符。
- GB18030 编码是一种多字节编码方式,可以表示汉字、拉丁字母、数字和其他特殊字符。
- GB18030 编码是中国大陆的国家标准字符集,也是国际上通用的字符编码方式之一。
内置函数原型
| 原型 | 功能 |
|---|---|
open(filepath, mode='r', buffering=-1, encoding=None, newline=None) | 打开文件 |
bin(number) | 获取数字的二进制 |
文件打开模式
| 字符串 | 含义 |
|---|---|
| 'r' | 以读的方式打开(默认) |
| 'w' | 以写的方式打开文件,会先清空文件 |
| 'x' | 创建一个新的文件,以写的方式打开,如果存在会报错 |
| 'a' | 以写的方式打开文件,如果文件已存在,就在文件最后位置追加内容 |
| 'b' | 以二进制方式打开,可以和读写命令共用 |
| 't' | 以文本方式(默认) |
| '+' | 以读和写方式打开文件,用于更新文件 |
open()函数的默认打开方式:mode='rt'
常用的文件操作方法
| 名称 | 功能 |
|---|---|
f.read() | 读取所有内容,光标移动到文件末尾 |
f.readline() | 读取一行内容,光标移动到第二行首部 |
f.readlines() | 读取每一行内容,存放于列表中 |
f.write('hello') | 针对文本模式的写,需要自己写换行符 |
f.write('111\n\n222'.encode('utf-8')) | 针对 b 模式的写,需要自己写换行符 |
f.writelines(['333\n', '444\n']) | 文件模式 |
f.writelines([bytes('333\n', coding='utf-8'), '444\n'.encode('utf-8')]) | b 模式 |
f.readable() | 文件是否可读 |
f.writable() | 文件是否可写 |
f.closed() | 文件是否关闭 |
f.encoding | 如果文件打开模式为 b,则没有该属性 |
f.flush() | 立刻将文件内容从内存刷到硬盘 |
控制文件位置指针
| 方法 | 功能 |
|---|---|
f.seek(x, 0) | 表示从起始位置,即文件首行首字符开始移动x个字符 |
f.seek(x, 1) | 表示从当前位置向后移动x个字符 |
f.seek(-x, 2) | 表示从文件的结尾向前移动x个字符 |
f.tell() | 获取当前文件光标的位置 |
中文字符的 Unicode 编码范围
科普
\u4e00~\u9fff或者0x4e00~0x9fff
range 函数
提示
前闭后开, 例如 range(26) => [0, 26)
字符串

format
format 简单介绍
format方法默认左对齐, 使用空格填充, 使用方式如下:

示例:
python
print("{:*^20,f}".format(1234.56789))
# 结果:****1,234.567890****random

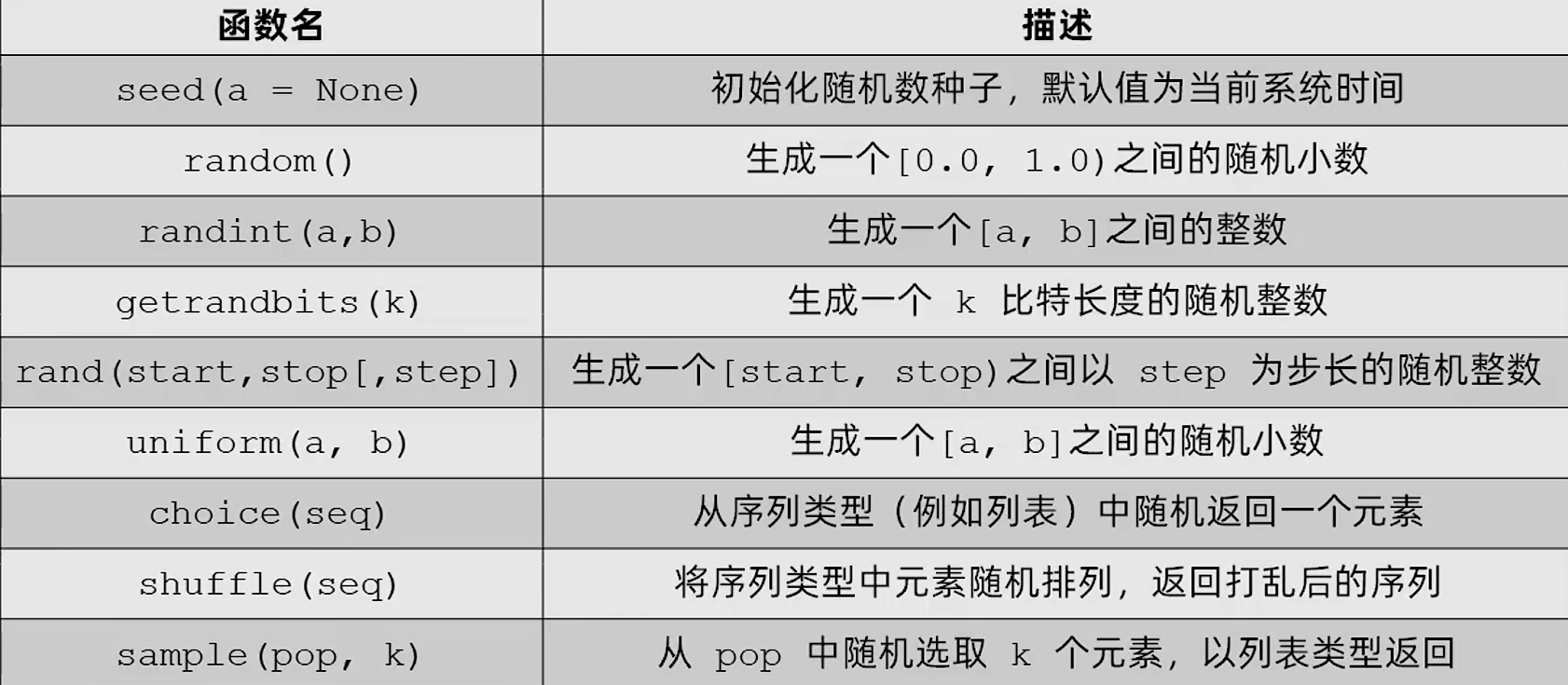
提示
random.seed(数字)设定随机数种子, random.randint(0, 25)是前后闭区间, 包含[0, 25].
列表

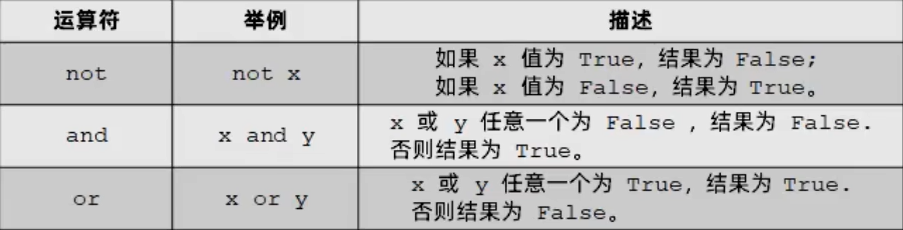
逻辑运算符
字符串操作符

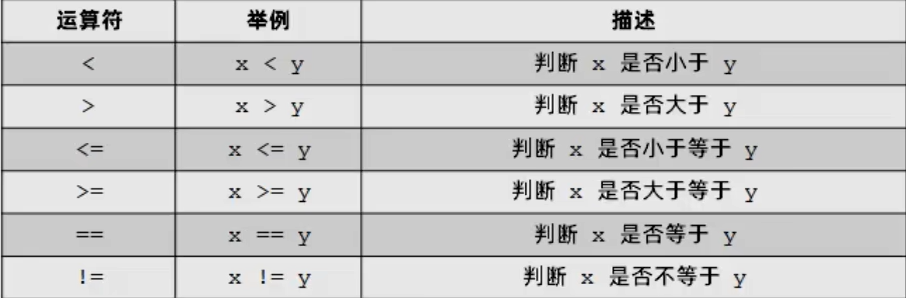
关系运算符
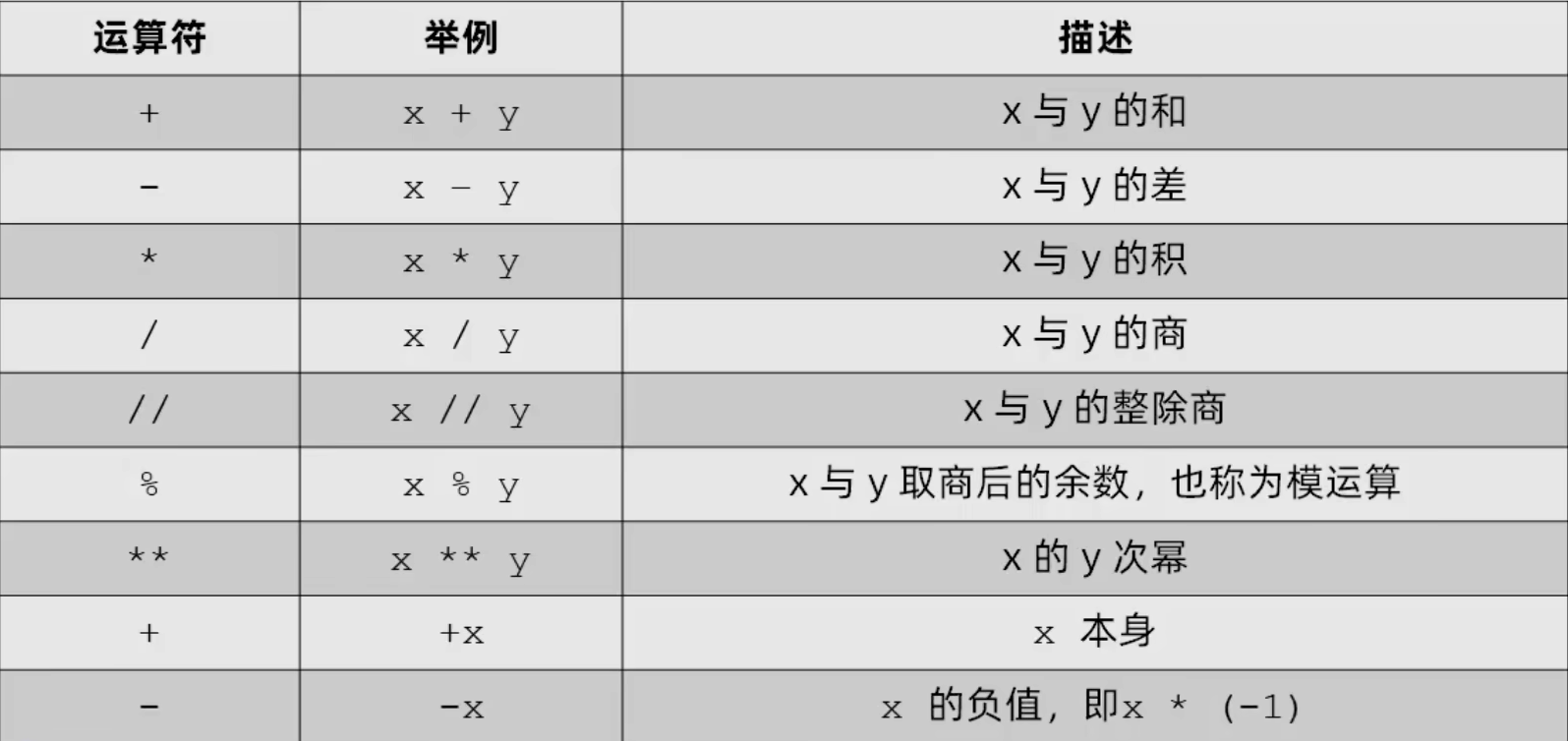
算术运算符
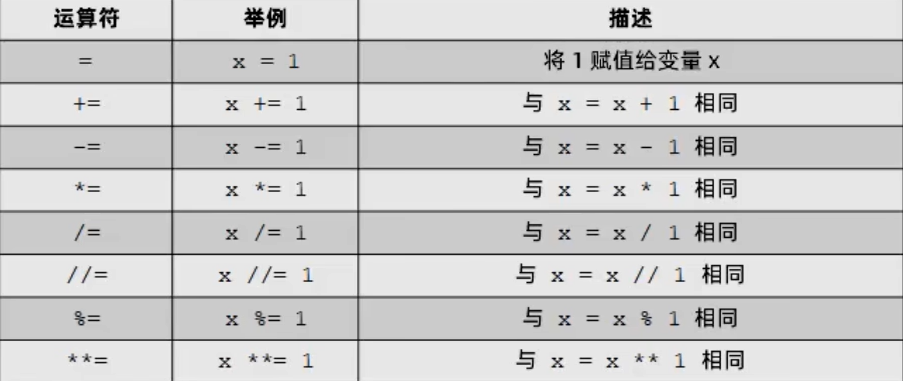
增强赋值操作符
转义字符输出
python
def escape_string():
# 转义字符
# %s 字符串
# %d 整数
# %f 浮点数(%.数字f 表示浮点数精度)
# %c 字符
# %o 无符号八进制
# %x 无符号十六进制(小写)
# %X 无符号十六进制(大写)
print("""姓名: %s,
数学成绩: %d,
总成绩: %.1f,
我的成绩转换为八进制是: %o,
转换为十六进制是: %X,
名是: %c"""
% ('小明', 98, 98.0, 98, 15, '玉'))常见格式化输出方式
python
def format_print():
"""
格式化输出方式
:return:
"""
score = 100
print("格式化字符输出, 如 %d" % (1, ))
print("{}".format(100)) # print("{:.2f}".format(100))
print(f"我的成绩: {score}")字符串常用函数

字符串常用处理方法
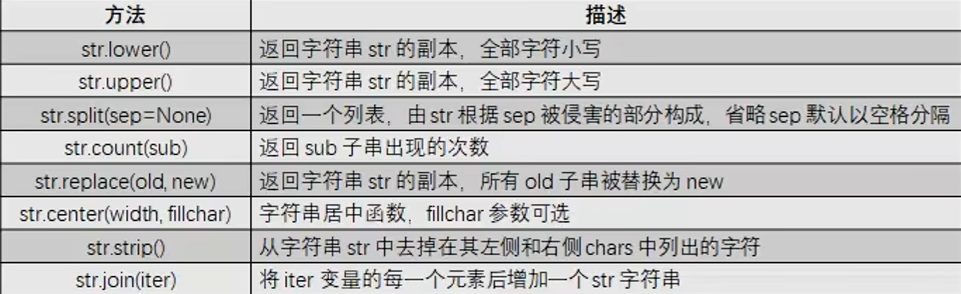
组合数据类型的特点
组合数据类型如下特点:
1. 集合(Set):
- 集合是一种无序且不重复的数据集合。
- 元素的顺序是不确定的,集合中的元素不会重复。
- 可以使用花括号
{}或者set()函数来创建集合。 - 集合是可变的,可以添加、删除元素,但集合本身是不可哈希的。
- 支持常见的集合操作,如并集、交集、差集等。
- 适合用于去重、检查成员资格等操作。
2. 列表(List):
- 列表是一种有序的可变数据集合。
- 列表中的元素可以重复,可以是不同类型的数据。
- 使用方括号
[]或者list()函数来创建列表。 - 列表是可变的,可以通过索引进行访问、修改、添加、删除元素。
- 支持切片操作,可以提取列表的子列表。
- 适合用于存储有序的、可以修改的数据集合。
3. 元组(Tuple):
- 元组是一种有序的不可变数据集合。
- 元组中的元素可以重复,可以是不同类型的数据。
- 使用圆括号
()或者tuple()函数来创建元组。 - 元组是不可变的,一旦创建就不能修改,不能添加或删除元素。
- 支持通过索引进行访问,但不支持修改元素。
- 适合用于存储不可变的、有序的数据集合,如函数的返回值、数据库查询结果等。
4. 字典(Dictionary):
- 字典是一种键值对的无序数据集合。
- 字典中的键必须是不可变的(通常是字符串、整数或元组),值可以是任意类型的数据。
- 使用花括号
{}或者dict()函数来创建字典,每个键值对用冒号:分隔。 - 字典是可变的,可以添加、删除键值对。
- 支持通过键来访问值,但不支持通过索引来访问。
- 适合用于存储具有映射关系的数据,如姓名与电话号码的对应关系等。
总结:
- 集合适用于无序且不重复的数据集合,用于去重、检查成员资格等操作。
- 列表适用于有序的、可变的数据集合,可以进行添加、删除和修改操作。
- 元组适用于有序的、不可变的数据集合,用于存储不可变的数据。
- 字典适用于键值对的无序数据集合,用于存储具有映射关系的数据。
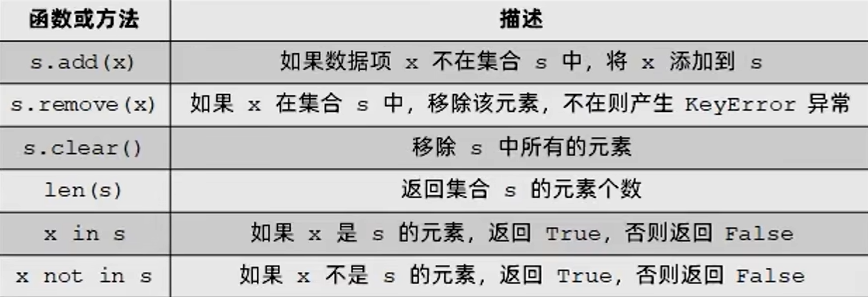
集合的操作符

集合的常用操作函数和方法
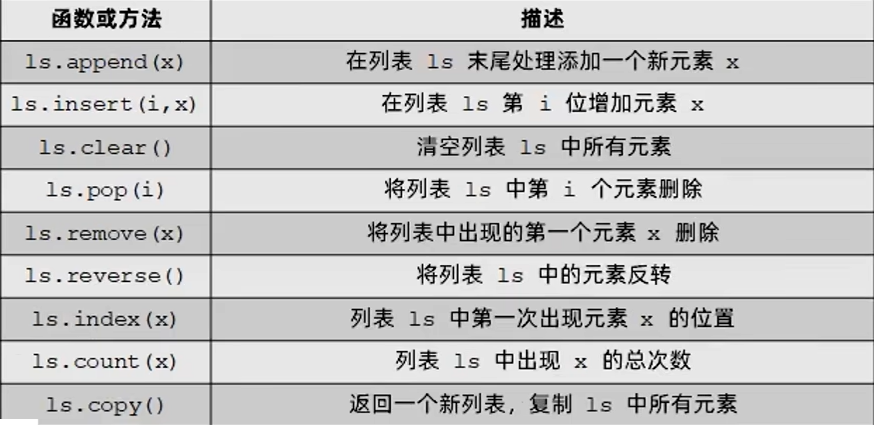
列表的常用操作方法
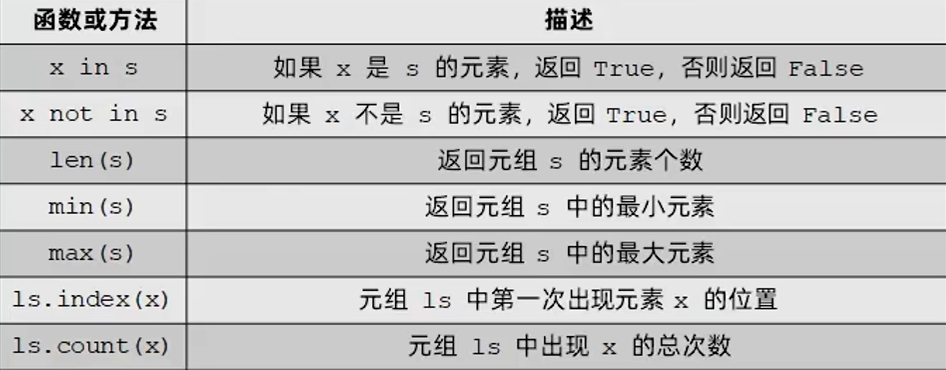
元组常用操作符与函数
字典类型常用操作方法
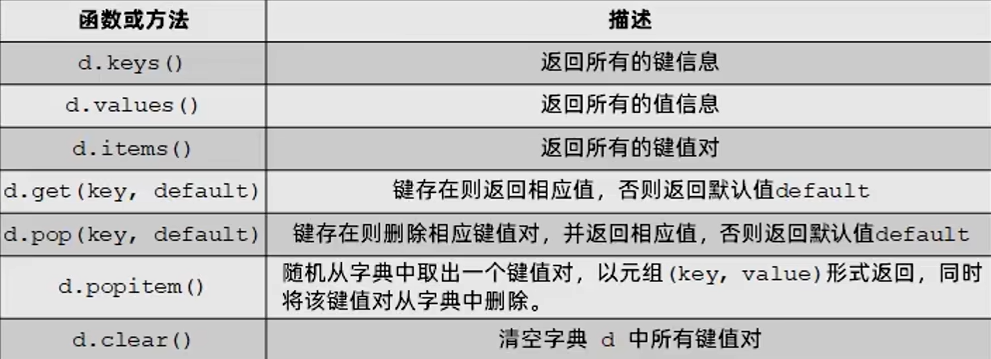
文件操作模式说明

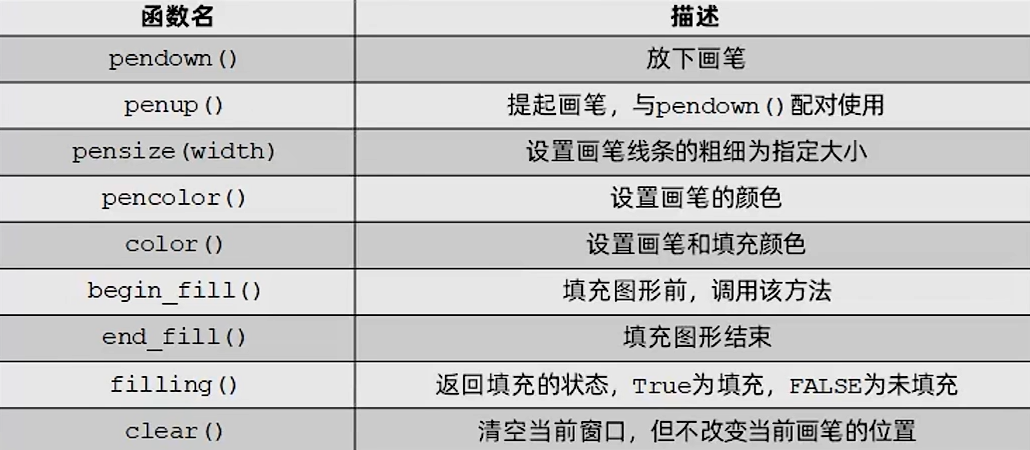
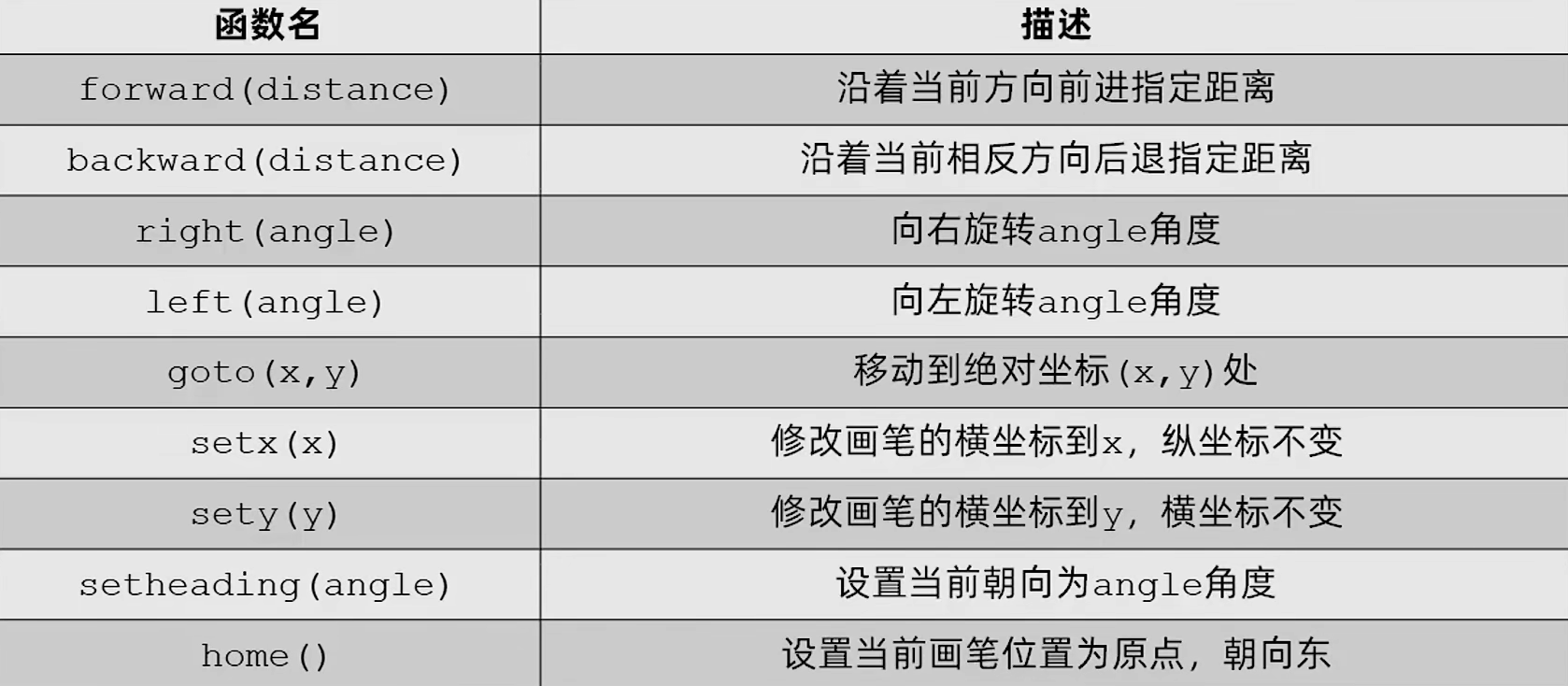
turtle 库常用函数

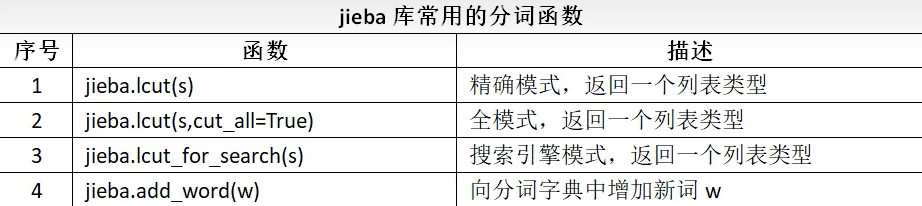
jieba 库常用函数
词云 库常用函数
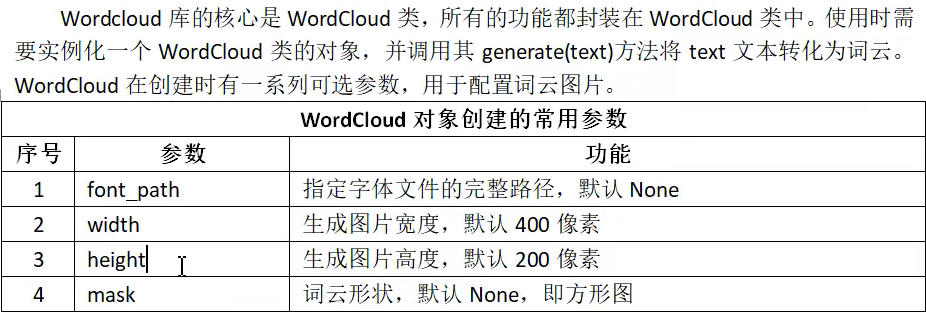
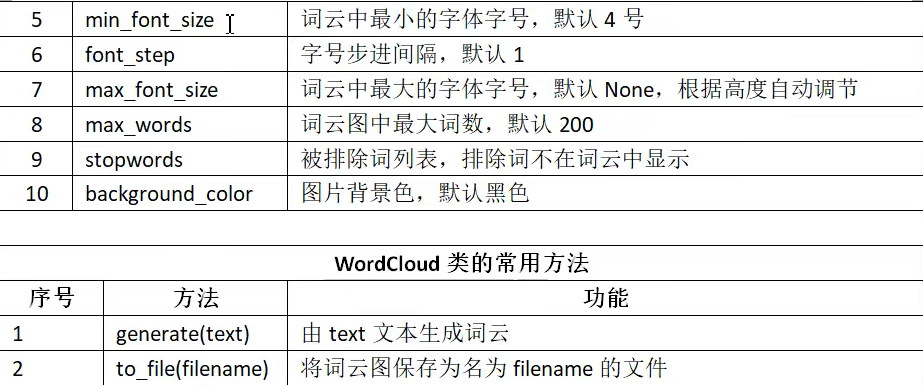
pyinstaller 库的使用
- 常用打包命令
python
$ pyinstaller -i favicon.ico --distpath bundle -F app.py --noconsole --clean简单功能区
turtle 绘图
绘制爱心
python
import time
import turtle as t
def heart(pen):
pen.setup(0.5, 0.75, 100, 100)
pen.ht() # 隐藏画笔 # 设置状态
pen.speed(1) # 设置速度
pen.width(20) # 设置画笔宽度, 等同于 pen.pensize() 方法, 值的大小可以改变爱心的圆润程度
pen.left(45) # 设置初始角度
pen.color('orangered') # 等同于 pen.pencolor()
pen.fillcolor('red') # 填充颜色
pen.begin_fill() # 准备填充颜色(在路径绘制出来之后)
# 开始绘制
pen.fd(100)
pen.circle(50, 180)
pen.right(90)
pen.circle(50, 180)
pen.fd(100)
pen.end_fill()
time.sleep(5)
if __name__ == '__main__':
print('123')
heart(t)日常编程练习题
九九乘法表
python
def multiplication_table():
"""
输出九九乘法表
:return:
"""
for i in range(1, 9 + 1):
for j in range(1, i + 1):
print(f'{i} * {j} = {i * j}', end='\t')
print()斐波那契数列
python
def fibonacci(position: int):
"""
获取斐波那契数列中的某个数: 高效算法
:param position: 斐波那契数列中的位置
:return:
"""
start = 1
end = 1
index = 2
if position <= 0:
return 0
elif 1 == position or position == 2:
return 1
else:
while index < position:
start, end = end, start + end
index += 1
return end
for i in range(1, 10000):
print(fibonacci(i), end=', ')注意细节
除法运算返回浮点数
python
print(4 / 2)
# 2.0复数运算
拓展:
复数运算的虚部必须输出, 即使虚部是
0也要输出, 实部是0可以不用输出.
通过
number.real获取实部,number.imag获取虚部.
python
print(complex(0))文件读写
read()、readline()、readlines()
python
with open('./test.txt', encoding='UTF-8') as f:
# read() 指定读取字符个数, 就返回指定的字符个数
# 不指定则返回文件全部内容
print(f.read(20))python
with open('./test.txt', encoding='UTF-8') as f:
# readlines() 返回所有行内容, 装到一个列表中
lines = f.readlines()[:2] # 取前两行的内容出来
print(lines)python
with open('./test.txt', encoding='UTF-8') as f:
# readline() 指定读取当前光标之后的多少个字符
# 不指定则返回当前光标所在位置到行尾的所有内容, 即遇到换行符 \n 就返回
print(f.readline(3))
print(f.readline())python
file_name = open('./test.txt', encoding='UTF-8')
for row in file_name.readlines():
print(row, end='')
# 上面的遍历 f.readlines() 可以简写成下面的方式: 直接遍历文件对象
file_name = open('./test.txt', encoding='UTF-8')
for row in file_name:
print(row, end='')txt
大家好, 欢迎学习
国家计算机二级考试Python
大家好, 欢迎学习
国家计算机二级考试Python
大家好, 欢迎学习
国家计算机二级考试Python
大家好, 欢迎学习
国家计算机二级考试Pythonseek()
python
# 改变当前文件操作指针的位置, offset的值:
# 0 为文件开头;
# 1为从当前位置开始;
# 2为文件结尾python
with open('./test.txt', encoding='UTF-8') as f:
# readlines() 返回所有行内容, 装到一个列表中
content = f.read() # 此时文件位置指针已经移到了最后的位置
print("content: ", content)
lines = f.readlines() # 所以这里读取的内容为空
print('第一次打印lines: ', lines)
# 此时可以将文件位置指针设置为开头, 那么才能读取出内容来
f.seek(0) # 设置文件位置指针为文件开头
lines = f.readlines()
print('第二次打印lines: ', lines)write()、writelines()
python
with open('./test2.txt', 'w', encoding='UTF-8') as f:
ls = ['天苍苍\n', '地荒荒\n', '日照三山\n', '夜半来\n', '风起云来\n', '花落知多少\n']
# write() 写入字符串, 执行一次写入行数并不会换行, 需要手动在每行末尾添加换行符
for s in ls:
f.write(s)python
with open('./test1.txt', 'w', encoding='UTF-8') as f:
ls = ['天苍苍\n', '地荒荒\n', '日照三山\n', '夜半来\n', '风起云来\n', '花落知多少\n']
# writelines() 可以将一个装载字符串对象中的内容写入文件
f.writelines(ls)函数可选参数的打包和解包
python
lst = ['1', '123', '456']
def unpacking(value, *args, **kwargs):
# 函数定义中的 *args 参数表示对调用函数时其他多余的参数打包成一个元组
# 函数体中使用的 *args 表示将形参 args 元组变成解包形式
print('value: ', value)
print("args: ", args)
print('*args: ', *args)
print('kwargs: ', kwargs) # 表示传入的关键字参数
print('*kwargs: ', *kwargs) # 解包出所有键
# print('**kwargs: ', **kwargs) # 错误
# 调用函数传入的 *lst 表示将传入的参数列表解包, 如果直接传入 lst, 那么就是等价于传入的是一个整体(的元素)
unpacking(0, *lst, x=15, y=10, animal='monkey')匿名函数 lambda
匿名函数功能
(1)避免文件中过多定义函数
(2)临时用, 临时定义, 用完即销毁
(3)按照参数和固定的表达式(公式)即可计算返回得到结果
(4)方便定义高阶函数
(5)即用即定义, 定义和使用可以直接写在一起
python
# 匿名函数的作用:
# (1)避免文件中过多定义函数
# (2)临时用, 临时定义, 用完即销毁
# (3)按照参数和固定的表达式(公式)即可计算返回得到结果
# (4)方便定义高阶函数
# (5)即用即定义, 定义和使用可以直接写在一起
sqrt = lambda x: x ** 2
print((lambda function: function(8))(sqrt))
print((lambda function: function(2))
(lambda x: x ** 2))常用方法总结
获取文件类型
根据文件名称获取文件类型
提示
(1)
string.endswith(substring)方法用来查找字符串末尾是否包含子串substring.
(2)
string.find(substring, start, end)方法在指定范围内查找子串字符串, 默认位置是从头到尾.end参数默认就是最后的位置, 如果需要从尾到前面某个位置查找, 就不要设置end值了, 否则会出现异常.
python
filename = '123.png.MP4'
if filename.find('.MP4', -4) != -1:
print(f'{filename}是一个视频')读取大文件
python
while True:
block = f.read(1024)
if not block:
breakpython
while True:
line = f.readline()
if not line:
break学习笔记区
panda 库使用
数据采集
数据免费采集网站:点击去这里
python
# 注意先创建一个 stock 的数据库, token来源于官网注册后在个人主页获取
import tushare as ts
from sqlalchemy import create_engine
# 1、设置token
ts.set_token("8e976b6d12919f5a7957eb46f0da9810eab4a582a2ee6eca1924b25b")
# 2、获取股票数据
df = ts.pro_bar(ts_code="000651.SZ", # 股票代码
start_date="20220101", # 起始时间
end_date="20230930") # 结束时间
""" 保存方式 """
# 3、保存到excel
df.to_excel('格力电器.xlsx')
# 4、保存到csv
df.to_csv('格力电器.csv', # 文件名
sep=',', # 间隔符
na_rep='9999', # 缺失值使用9999代替
header=True, # 保留列名
index=False) # 不保留索引
# 5、保存到数据库
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/stock?charset=utf8') # 配置数据库连接引擎
df.to_sql('glee', # 表名
con=engine, # 数据库连接引擎
if_exists='replace', # 如果表已经存在,使用 replace 会删除表,重新创建表并插入数据
index=False) # 不存储行索引- 读取数据, 操作 DataFrame 数据
python
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/stock?charset=utf8') # 配置数据库连接引擎
# 读取xlsx文件
# df = pd.read_excel('格力电器.xlsx', sheet_name='Sheet1')
# print(df)
# 读取数据库
# df = pd.read_sql_table('glee', con=engine)
# print(df)
# 读取数据库: 通过查询语句来读取数据
# df = pd.read_sql_query('select * from glee', con=engine)
# print(df)
# 读取数据库, 可以写表名,也可以写sql语句
# df = pd.read_sql('glee', con=engine)
# print(df)
# 常用属性
# DataFrame: values, index, columns, ndim, size, shape, dtypes, T
# df = pd.DataFrame([[1, 2], [3, 4]], index=[0, 1], columns=['A', 'B'])
# print(df)
df = pd.read_sql_table('glee', con=engine)
# values 二维数组的每个元素为一行的数据
# print(df.values)
# index 获取所有行名组成的列表
# print(df.index)
# columns 获取所有列名组成的列表
# print(df.columns)
# ndim 获取该对象的总维度
# print(df.ndim)
# shape 获取矩阵的行列数(行数, 列数)
# print(df.shape)
# size 获取矩阵的元素个数
# print(df.size)
# T 置换数组: 返回一个新的置换矩阵, 原矩阵无变化
print(df.T)
print(df)数据存储
- 存储到 CSV 文件中
原型
python
DataFrame.to_csv(path_or_buf=None, sep=",", na_rep="", columns=None, header=True, index=True, encoding=None)| 参数 | 描述 |
|---|---|
| path_or_buf | 指定文件存储路径 |
| sep | 设置分隔符,默认为逗号 |
| na_rep | 设置遇到缺失值的替代字符,默认为空字符 |
| columns | 设置需要保存的列,默认为 None(全选) |
| header | 设置是否保留列名,默认为 True |
| index | 设置是否保留索引,默认为 True |
| encoding | 设置文件编码格式,默认为 UTF-8 格式 |
示例
python
df.to_csv('格力电器.csv', # 文件名
sep=',', # 间隔符
na_rep='9999', # 缺失值使用9999代替
header=True, # 保留列名
index=False) # 不保留索引- 存储到 Excel 文件中
原型
python
DataFrame.to_excel(excel_writer=None, sheetname=None, na_rep="", columns=None, header=True, index=True, encoding=None)| 参数 | 描述 |
|---|---|
| excel_writer | 指定文件路径或者 ExcelWriter 对象 |
| sheetname | 设置 sheet 名称,默认为 Sheet |
| na_rep | 设置在遇到 NaN 值的替代字符,默认为空字符 |
| columns | 设置需要保存的列,默认为 None(全选) |
| header | 设置是否保留列名,默认为 True |
| index | 设置是否保留索引,默认为 True |
| encoding | 指定文件编码格式 |
示例
python
df.to_excel('格力电器.xlsx')- 存储到数据库
信息
MySQL数据库官网:去下载
原型
python
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)| 参数 | 描述 |
|---|---|
| name | 设置表名称。string 型,无默认值 |
| con | 设置数据库连接对象,无默认值 |
| if_exists | 设置表名已存在时的处理方法,可设为'fail'、'replace'、'append'。分别表示失败、替换、追加新值到已有表中。 |
| index | 设置是否将索引写入都表中。值为 boolean 类型,默认为 True |
| index_label | 设置索引的名称,如果该参数为 None 且 index 为 True,则使用索引名。如果为多重索引,则应该使用 sequence 形式。默认为 None |
| chunksize | 设置一次要写入的行数。默认将所有行一次写入。值为 int 型,可选 |
| dtype | 设置写入的数据类型。值为 dict 型(列名为 key,数据格式为 value)或标量(应用于所有列)。默认为 None |
示例
python
df.to_sql('glee', # 表名
con=engine, # 数据库连接引擎
if_exists='replace', # 如果表已经存在,使用 replace 会删除表,重新创建表并插入数据
index=False) # 不存储行索引技能提升
Pandas 不仅可以将 DataFrame 数据保存到文本文件、Excel 文件以及数据库中,还可以保存为更多文件类型。如下表:
| 文件类型 | 函数 | 说明 |
|---|---|---|
| 文本文件 | to_csv() | 该方法可以将数据保存为 CSV、TXT 等文本文件格式 |
| Excel 文件 | to_excel() | 该方法支持将数据保存为 Excel 文件格式 |
| 数据库 | to_sql() | 该方法支持将数据保存到 MySQL、Oracle、SQL Server 和 SQLite 等主流数据库中 |
| pickle 文件 | to_pickle() | 该方法支持 Python 将数据序列转化为二进制文件格式 |
| HDF 文件 | to_hdf() | HDF(Hierarchical Data Format)可以存储不同类型的图像和数码数据,并且可以在不同类型的机器上传输 |
| JSON 文件 | to_json() | JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,非常适用于服务器与 JavaScript 的交互 |
| HTML 文件 | to_html() | HTML(HyperText Markup Language,超文本标记语言)是一种用于创建网页的标准标记语言 |
数据读取
说明
Pandas 也提供了相应的函数用于从文本文件、Excel 文件以及 MySQL 数据库中读取数据。提供读取各种文件类型的函数如下表:
| 文件类型 | 函数 | 说明 |
|---|---|---|
| 文本文件 | read_table()、read_csv() | 读取文本文件的数据,如 CSV、TXT 文件 |
| Excel 文件 | read_excel() | 读取 Excel 文件的数据 |
| 数据库 | read_sql_table()、read_sql()、read_sql_query() | 读取数据库表中的数据。read_sql_table通过表名读取整张表,read_sql_query通过 SQL 语句实现对数据库中表的操作,read_sql兼具前两者的功能 |
| pickle 文件 | read_pickle() | 读取 pickle 文件的数据 |
| HDF 文件 | read_hdf() | 读取 HDF 文件的数据 |
| JSON 文件 | read_json() | 读取 JSON 文件的数据 |
| HTML 文件 | read_html() | 读取 HTML 文件的数据 |
- 读取 CSV 文件
原型
python
pd.read_csv(filepath_or_buffer, sep=',', header='infer', names=None, index_col=None, usecols=None, dtype=None, skiprows=None, nrows=None, encoding=None)| 参数名称 | 描述 |
|---|---|
| filepath_or_buffer | 设置文件路径 |
| sep | 设置分隔符。默认为逗号,read_table默认为制表符 |
| header | 设置第几行作为列名,默认为 0(第一行),如果文件没有标题行,则设置为 None |
| names | 设置自定义的列名,默认为 None |
| index_col | 设置某一列作为 DataFrame 的行名,如果没有这样的列,则设置为 None |
| usecols | 读取按列划分的子集,有以下两种取值。None:读取所有列,默认值;列表:如[0,2,4]表示列的索引,['ts_code', 'high']表示列名 |
| dtype | 设置读取的数据类型(列名为 key,数据格式为 values)。默认为 None |
| skiprows | 设置开头要跳过的行数,默认为 None(不跳过任何行) |
| nrows | 设置要读取数据的行数,默认为 None(全部读取) |
| encoding | 设置读取的编码格式 |
示例如果设置了skiprows,需要设置header=None或者names=[...],否则就会默认将新的第一行数据作为 DataFrame 的列标签名。
python
df = pd.read_csv('格力电器.csv',
skiprows=1, # 忽略第一行的列名
names=[chr(i) for i in range(65, 65 + 11)], # 自定义列名
)
print(df)- 读取 Excel 文件
原型
python
pd.read_excel(io, sheet_name=0, header=0, index_col=None, names=None, dtype=None)| 参数名称 | 描述 |
|---|---|
| io | 文件路径 |
| sheet_name | sheet 表名或者位置,索引从 0 开始。接收 string、int 或 list 型 |
| header | 设置第几行作为列名,默认为 0(第 1 行),如果文件没有标题行,则设置为 None |
| index_col | 设置某一列作为 DataFrame 的行名,如果没有这样的列,则设置为 None |
| names | 设置自定义的列名,默认为 None |
| dtype | 代表读取的数据类型(列名为 key,数据格式为 values)。默认为 None |
| usecols | 读取按列划分的子集。划分的范围有以下几种方法,(1)None:读取所有列,默认的。(2)字符串:如'A:E'表示读取列 A 到列 E 子集所有的数据。(3)列表:[0,2,4]表示列的索引,['ts_code', 'high']表示列名 |
| skiprows | 开头要跳过的行数,默认为 None(不跳过任何行) |
| nrows | 要读取数据的行数,默认为 None(全部读取) |
示例
python
df = pd.read_excel('格力电器.xlsx', # 读取excel文件
sheet_name='Sheet1', # Excel中的sheet名称
index_col=0 # 将第一列作为行名
)
print(df)- 获取 MySQL 数据库中的数据
原型
python
pd.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)python
pd.read_sql_query(sql, con, index_col=None, coerce_float=True, parse_dates=None, params=None, chunksize=None)python
pd.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)| 参数名称 | 描述 |
|---|---|
| sql 或 table_name | string 型。读取数据表的表名或 SQL 语句 |
| con | 数据库连接对象 |
| index_col | 设置某一列作为 DataFrame 的行名,如果没有这样的列,则设置为 None |
| coerce_float | boolean 型。将数据库中的 decimal 类型的数据转换为 Pandas 的 float64 类型数据,默认为 True |
| parse_dates | list 或 dict 型。解析为日期的列名 |
| columns | list 型。要从 SQL 表中读取列名的列表(仅在读取表时使用)。默认为 None |
完整显示表的数据
python
from pandas import set_option
# 1.设置显示宽度为380
set_option("display.width", 380)
# 2.设置最大列数
set_option("display.max_columns", None)
# 3.设置最大行数,None为显示全部行
set_option("display.max_rows", None)numpy 库使用
python
import numpy as np
# 1、初始化创建一个 `3行2列` 全0的数组
n1 = np.zeros((3, 2)) # np.ones((3, 2)) 创建一个 `3行2列 全1的数组`
print(n1)
# 2、shape来获取数组的尺寸
print(n1.shape)
# 3、`np.arange(3, 7)` 创建一个递增或递减的数列, 前闭后开区间, 类似于python的range行数
n2 = np.arange(-5, -1)
print(n2)
# 4、`np.linspace(1, 10, 5)` 创建一个介于某个区间等间距分布的数, 类似于一个等差数列, 最后一个表示要输出样本的总个数
n3 = np.linspace(0, 6, 4)
print(n3)
# 5、通过`np.random.rand(3, 2)` 创建一个3行2列的随机数组, 生成的随机数范围是[0, 1)
n4 = np.random.rand(3, 2)
print(n4)
# 6、在 numpy 中数组默认的数据类型是 64位 的浮点数(np.float64), 可以通过 dtype 参数来指定其他的数据类型
# 现有数据可以通过 n4.astype(int) 方法转换为其他数据类型
n5 = np.ones((3, 2))
print(type(n5[1, 1])) # numpy.float64
n5 = n5.astype(int)
print(type(n5[1, 1]))
# 7、基本运算
# 相同尺寸的数组可以进行常见的数学运算, 会将相同位置的数据进行相应的运算
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(a + b)
print(a / b)
# 8、乘法运算中的 dot 点乘运算
print(np.dot(a, b))
# @ 符号 => 它会进行矩阵的乘法运算, 等同于 np.matmul() 函数, 而不是将对应的元素简单相乘
print(a @ b)
# 9、开平方运算, 对所有元素进行开平方运算
print(np.sqrt(a))
# 10、使用 np.cos()、np.sin() 进行三角函数运算
# 11、使用 np.log(a) 进行对数运算、np.power(a, 2) 进行指数运算, a * 5 也可将数据全部进行乘法运算 => 这个操作也称作`广播`
# 12、使用 a.min() 返回数组中最小的元素, a.max() 返回数组中最大的元素, a.sum() 返回数组中所有数据的总和
# 13、a.mean()、np.median(a) 返回数组中所有元素的平均值、中位数, 通过 axis = 0 指定列, axis = 1 指定行
# 14、a.var()和 a.std() 会返回数据的方差和标准方差
# 15、通过逻辑运算符组合不同的条件
arr = np.arange(10)
print(arr[(arr > 3) & (arr % 2 == 0)]) # numpy 中的逻辑与用 &, 逻辑或用 |
# 16、通过 arr[一维切片, 二维切片, ...]
a = np.array([[1, 2, 3],
[4, 5, 6]])
print(a[0, :]) # 如果要的维度中的元素全都要, 冒号可以省略, 如 a[0]python
arr = np.arange(10, 20, 2)
print(arr)matplotlib 库学习
- 常用函数的功能
| 函数 | 作用 |
|---|---|
| plt.title() | 设置标题 |
| legend(['1 月份', '2 月份'], loc='upper center') | 显示图例 |
| xlabel(str) | x 轴标题 |
| ylabel(str) | y 轴标题 |
| xticks(x, x_label) | x 轴刻度序列及刻度标记 |
| grid() | 显示网格 |
| figure(figsize=(12, 10)) | 设置画布宽高 |
| subplot(221) | 表示绘制在 2x2=4 的子图方块的第一块区域 |
| plot(x, y, color, linewidth) | 绘制折线图 |
| bar(x, y, color, alpha=0.2) | 绘制条形图 |
| scatter(x, y, c='r', marker='*') | 绘制散点图 |
| pie(x, explode, labels, colors, autopct="%1.1f%%") | 绘制饼图 |
| show() | 展示图形 |
- matplotlib 绘图四部曲
python
import matplotlib.pyplot as plt
import numpy as np
# 设置支持中文格式
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1、读取数据(对需要的行列数据进行提取)
# 如果数据中混杂有非数字的列数据,那么将读取的数据类型设置为dtype=str即可, skiptrows跳过一行(将第一行去掉)
data = np.loadtxt('xxx/xxx.csv', dtype=str, delimiter=',', skiprows=1)
# todo...
# 2、添加内容(丰富图表)
plt.title("2017年1月份AQI走势")
plt.xlabel("日期")
plt.ylabel("AQI值")
x_label = [str(int(i)) for i in x] # 设置x轴刻度,对应的还可以设置y轴刻度
plt.xticks(x, x_label[, rotation=-45]) # 设置X轴名称(文字倾斜角度,默认逆时针)
plt.legend(['1月AQI走势图', '2月AQI走势图']) # 图例
plt.grid() # 显示网格
# 3、绘制图形
plt.plot(x, y, color)
# 4、显示图形
plt.show()python 库的使用
psutil
介绍
psutil(python 系统和流程实用程序)是一个跨平台库,用于在Python 中检索有关正在运行的 进程和系统利用率(CPU,内存,磁盘,网络,传感器)的信息。它主要用于系统监视,分析,限制进程资源和运行进程的管理。它实现了 UNIX 命令行工具提供的许多功能,例如:ps,top,lsof,netstat,ifconfig,who,df,kill,free,nice,ionice,iostat,iotop,uptime,pidof,tty,taskset,pmap。
安装
bash
$ pip install psutil快速上手
python
# 导入
import psutil as psCPU
- 获取 CPU 逻辑核数,
logical参数默认为True,指获取逻辑核数
python
ps.cpu_count(logical=True) # 4- 查看 CPU 物理核数
python
ps.cpu_count(logical=False)- 以百分比的形式返回表示当前 CPU 的利用率的浮点数。
interval参数必须设置为大于 0,因为它测试的是时间间隔内的利用率。percpu参数为True则所有 CPU 利用率的浮点列表,列表的顺序在调用之间是一致的。
python
ps.cpu_percent(interval=1, percpu=True) # 返回1秒内的每个核的利用率,percpu=False,则返回所有CPU总的利用率等信息- 在特定模式下,返回 CPU 所花费的时间百分比。
python
ps.cpu_times_percent(interval=1, percpu=True) # 返回每个逻辑核用户、系统、中断、空闲等各种占用情况下的时间使用信息- 在特定模式下,返回 CPU 所花费的时间(单位为秒)。
python
ps.cpu_times() # 综合统计CPU在用户、系统、中断、空闲等占用情况下的时间使用信息- 将各种 CPU 统计信息作为命名元组返回。
python
ps.cpu_stats() # 返回CPU上下文切换、中断、软中断、系统调用信息内存
- 获取内存使用情况,需要注意的是,已使用和可用不等于总和。
- total,总大小。
- available,可用内存。
- used,已使用。
- free,空闲。
- percent,使用率。
python
ps.virtual_memory() # 返回内存总空间、可用空间、使用率、已使用、空闲的大小情况,单位是字节,如果需要转换为MB单位,需要获取到对应的属性值除以(0b01 << 20)获取交换分区内存统计信息。相关参数,单位(字节)
total,总大小。
used,已使用地 swap 内存。
free,空闲。
sin,系统累计从磁盘交换的字节数。
sout,系统累计从磁盘换出的字节数。
python
ps.swap_memory() # 返回以上信息磁盘
- 返回所有磁盘分区信息。包括设备,挂载点和文件系统类型。
python
ps.disk_partitions(all=False)
"""
[
sdiskpart(device='C:\\', mountpoint='C:\\', fstype='NTFS', opts='rw,fixed'),
sdiskpart(device='D:\\', mountpoint='D:\\', fstype='', opts='cdrom'),
sdiskpart(device='E:\\', mountpoint='E:\\', fstype='NTFS', opts='rw,fixed'),
sdiskpart(device='F:\\', mountpoint='F:\\', fstype='NTFS', opts='rw,fixed')
]
"""- 返回指定磁盘的信息。相关参数,单位(字节)
- total,总大小。
- used,使用。
- free,空闲。
- percent,使用率。
python
# 获取指定磁盘的使用情况
print(psutil.disk_usage('C:\\')) # sdiskusage(total=128034672640, used=98790318080, free=29244354560, percent=77.2)
# 循环遍历,从磁盘分区的对象中取出设备名称,再对其读取信息
for d in psutil.disk_partitions():
if d[3] != 'cdrom': # 排除windows中的cd驱动器
item = psutil.disk_usage(d[0])
print('磁盘 {0} 总大小 {1[0]} 使用 {1[1]} 空闲 {1[2]} 使用率 {1[3]}'.format(d[0], item))- 获取磁盘
I/O统计信息。相关参数 - read_count,读取次数。
- write_count,写入次数。
- read_bytes,读取的字节数。
- write_bytes,写入的字节数。
python
ps.disk_io_counters()网络
获取网络
I/O信息。相关参数:bytes_sent:发送的字节数
bytes_recv:接收的字节数
packets_sent:发送的包数
packets_recv:接收的数据包数
errin:接收时的错误总数
errout:发送时的错误总数
dropin:丢弃的传入数据包总数
dropout:丢弃的传出数据包总数(macOS 和 BSD 总是 0)
python
ps.net_io_counters()- 获取网卡地址相关信息。相关参数:
参数信息
- family:地址族,AF_INET或AF_INET6, 或者
psutil.AF_LINK指 MAC 地址。 - address:主 NIC 地址(始终设置)。
- netmask:网络掩码地址(可能是
None)。 - 广播:广播地址(可能是
None)。 - ptp:代表“点对点”; 它是点对点接口(通常是 VPN)上的目标地址。广播和ptp是互斥的。可能是
None。
python
ps.net_if_addrs()进程
- 获取系统进程 pid
python
import os
import psutil
psutil.pids() # 以列表的形式返回系统所有进程pid号
print([{psutil.Process(pid).name(): pid} for pid in psutil.pids()]) # 返回进程名称和pid的列表
os.system('taskkill /F /IM wmplayer.exe') # 借助os模块强制杀死指定进程- 获取系统开机时间
python
import time
import psutil
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(psutil.boot_time()))) # 2019-05-28 08:16:31- 获取当前用户登录信息
python
print(psutil.users()) # [suser(name='Anthony', terminal=None, host='0.0.0.0', started=1559002601.0, pid=None)]- linux 系统返回硬件温度。
python
print(psutil.sensors_temperatures()) # windows下抛出AttributeError: module 'psutil' has no attribute 'sensors_temperatures'- linux 获取硬件风扇转速。
python
print(psutil.sensors_fans())电池
- 返回电池信息。相关参数:
参数
- 百分比:电池剩余百分比。
- secsleft:电池电量耗尽前剩余的秒数的粗略近似值。如果连接了交流电源线,则设置为
psutil.POWER_TIME_UNLIMITED。如果无法确定它被设置为psutil.POWER_TIME_UNKNOWN。 - power_plugged:
True如果连接了交流电源线,False如果没有,或者None无法确定。
python
print(psutil.sensors_battery()) # sbattery(percent=100, secsleft=<BatteryTime.POWER_TIME_UNLIMITED: -2>, power_plugged=True)